クエリファンアウト(Query Fan-out)とは?仕組みやSEO・LLMOでの重要性を解説


クエリファンアウトとは
クエリファンアウト(query fan-out)とは、ユーザーが1つキーワードを入れた裏で、AIが関連する複数の検索を自動実行し、結果をまとめて1つの回答にする検索手法です。
Google AI Mode だけでなく、ChatGPT Search や Perplexity、社内向けのAI検索ツールでも使われる、LLM時代の標準的な検索パターンとなっています。生成AI時代の最適化手法そのものは、当社メディアリーチ公開のLLMO(大規模言語モデル最適化)の定義と全体像も合わせて確認すると、本記事の位置付けがわかりやすいかと思います。
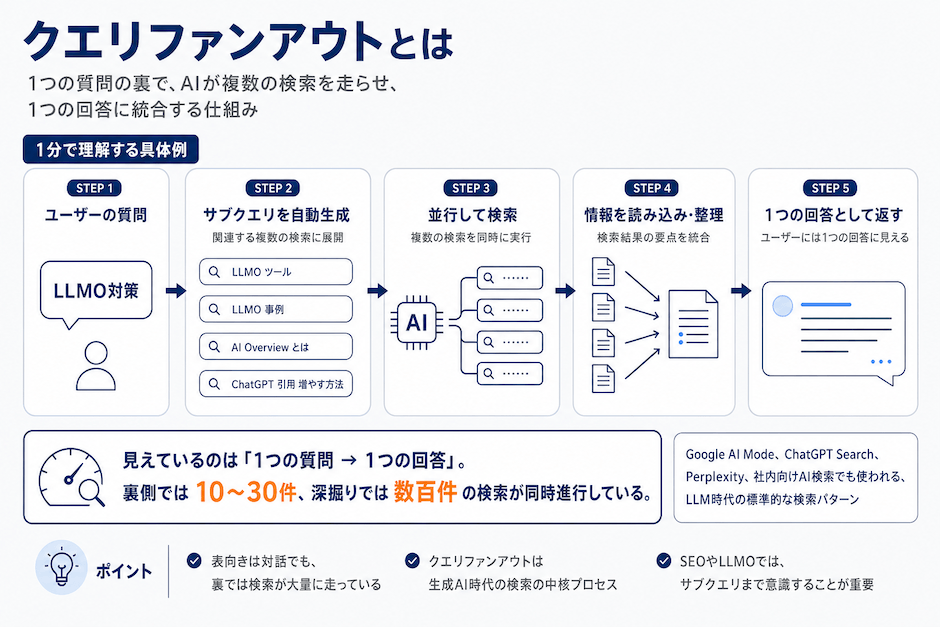
1分で理解するクエリファンアウト(query fan-out)の具体例
たとえばユーザーが「LLMO対策」とAIに質問した場合、裏ではAIが次のように動きます。
- 「LLMO対策」だけを検索するのではなく、AIが内部で関連する複数の検索(=サブクエリ)を自動生成する
例: 「LLMO ツール」「LLMO 事例」「AI Overview とは」「ChatGPT 引用 増やす方法」など - それぞれのサブクエリで検索を並行して実行する
- 集まった検索結果のページをAIが読み込み、1つの統合された回答に整理してユーザーに返す
ユーザーから見えるのは「1つの質問→1つの回答」だけですが、AIの裏では10〜30件、深掘り検索なら数百件の検索が同時進行している、というイメージです。
ユーザー側の体験が「検索」から「対話で尋ねる」へ変化している件は「検索」と「尋ねる」は何が違うのか──生成AIと検索エンジンの本質的な違いでも整理していますが、クエリファンアウトはその裏側で起きている技術プロセスにあたります。
クエリファンアウトの公式定義(Google公式の表現)
Googleは2025年5月のGoogle I/Oで、AI Modeのクエリファンアウトを公式に定義しました。Google公式ブログ「AI Mode in Search update」では「AI Modeはクエリファンアウト技術を使い、質問をサブトピックに分解して、ユーザーの代わりに多数の検索を同時に発行する」と明記されています。
同記事では Deep Search(深掘り調査機能)について「同じクエリファンアウト技術をさらに進化させたもので、数百件の検索を発行する」とも書かれています。通常のAI Mode で10〜30件、Deep Searchでは数百件のサブクエリが派生する、というスケール感を覚えておくと十分です。
クエリファンアウトの仕組み(3ステップで読み解く)
クエリファンアウトの3ステップ:分解→並列検索→統合
クエリファンアウトの動きは「(1)分解 → (2)並列検索 → (3)統合」の3ステップで整理できます。各ステップが具体的に何をしているか、Googleの特許と公式情報をもとに見ていきましょう。
ステップ1: AIが質問をサブクエリに分解
ユーザーが入れた1つの質問を、AIが内部で複数の小さな検索(=サブクエリ)に分解する工程です。
Google特許 US20240289407A1(“Search with stateful chat”、2024年公開)では、これを「synthetic queries(合成クエリ)」「additional/alternative queries(追加・代替クエリ)」と呼んでいます。
具体的には「代替クエリ提案、補完クエリ、ユーザークエリの書き換え版、ドリルダウンクエリなどでありうる」と定義されており、要するにAIが質問を様々な角度から言い換えて複数の検索を作る仕組みです。
ステップ2: 並列検索で情報収集
ステップ1で生まれたサブクエリを、AIが同時に検索エンジンに投げる工程です。
前述のGoogle公式ブログが「多数のクエリを同時発行する」と述べる部分にあたります。AI Mode の通常実行で10〜30件、Deep Searchでは数百件のサブクエリが同時に走ります。
検索対象はWebページだけではありません。同公式ブログによれば、AI Mode は Google Shopping Graph(500億点超の商品情報、1時間あたり約20億回更新)、Knowledge Graph、Maps などのデータベースも横断します。「Webだけでなく構造化データやエンティティDBも見にいく」と理解しておけば十分です。
ステップ3: 結果を統合して回答生成
並列検索で集めた大量のページから、AIが回答に使う情報を選別して1つの統合回答にまとめる工程です。
ここで重要なのは、検索で集めたページの全部が回答に引用されるわけではない点です。前述の特許 US20240289407A1では「クエリと追加クエリの両方に応答する複数の検索結果ドキュメントが、回答生成用ドキュメント集合として選定される」と書かれており、AIは回収したページの中から「最終回答に使うサブセット」を選び直します。
参照されたが引用されないページが大量に発生する——この事実が、後で出てくる「AI引用 vs AIブランド推薦」の議論につながります。
クエリファンアウトを採用しているAI検索エンジン
クエリファンアウトはGoogle固有の技術ではなく、主要なAI検索や検索系OSSが横断的に採用している共通パターンです。
まず採用事例の全体像を一次情報源とともに整理し、そのうえでGoogleの発明ではなく研究コミュニティ発の汎用手法であることを確認していきましょう。
クエリファンアウト採用事例表
| 採用主体LMM | カテゴリ | 該当機能・実装名 | 参考 |
|---|---|---|---|
| Google AI Mode / AI Overviews | 商用AI検索 | “query fan-out technique”(公式名称) | Google公式ブログ(I/O 2025) |
| ChatGPT Search(OpenAI) | 商用AI検索 | 内部で複数の検索クエリを生成・統合 | OpenAI公式 “Introducing ChatGPT search” |
| Perplexity AI | 商用AI検索 | Pro Search の multi-step reasoning | Perplexity公式ヘルプ “What is Pro Search” |
| Microsoft Copilot / Bing | 商用AI検索 | Bing Generative Search で複数検索を内部発行 | Microsoft Bing公式発表 |
| Anthropic Claude | 商用LLM | Web search ツールで関連クエリを動的発行 | Claude Web Search Tool 公式ドキュメント |
| RAG-Fusion | OSS / 学術 | 複数クエリ生成+RRF(順位融合) | arXiv:2402.03367 |
| LangChain | OSS RAG | MultiQueryRetriever(複数バリアントを自動生成) | LangChain公式リファレンス |
| LlamaIndex | OSS RAG | SubQuestionQueryEngine(サブ質問に分解) | LlamaIndex公式ドキュメント |
| Glean ほか | エンタープライズ検索 | 業務AI検索でのmulti-query拡張 | Glean公式 |
ここから読み取るべきポイントは2つです。
第一に、クエリファンアウトは事実上の業界標準であること。
第二に、LLMOの対策対象は「Google AI Modeだけ」ではなく、ChatGPT・Perplexity・Copilot・社内AI検索を含めたLLM経由の検索チャネル全体だということです。Google側の動きだけを深掘りしたい場合はGoogle検索でAI Modeがデフォルト化した世界で起こることを参照してください。
Googleの発明ではなく、研究コミュニティ発の汎用手法
クエリファンアウトはGoogleが独自に発明したものではありません。学術的な原型はarXiv:2402.03367(RAG-Fusion論文、Rackauckas, 2024年)で、複数クエリ生成と結果融合(Reciprocal Rank Fusion)を組み合わせる手法を体系化した最初期の論文です。これが LangChain MultiQueryRetriever と LlamaIndex SubQuestionQueryEngine としてOSSに標準実装され、ChatGPT Search や Perplexity Pro Search にも横展開されてきた流れです。サーベイ論文arXiv:2509.07794(Query Expansion Survey、2025年)も、LLMによるクエリ拡張がRAG全般で効果を発揮すると報告しており、業界横断の標準パターンであることが学術的にも裏付けられています。
クエリファンアウトとRAG・従来検索の違い
クエリファンアウトを正しく位置付けるためには、「従来のSEO検索」「RAG」との違いを整理しておく必要があります。
AI検索と従来のSEO検索との違い
従来のSEO検索は「ユーザーが入れた1つのキーワードに対して、ランキングアルゴリズムが上位10件を表示する」という1対多の構造でした。
クエリファンアウトでは、AIが入力クエリを内部で複数のサブクエリに展開し、それぞれの検索結果を統合して1つの回答に再構成します。つまり「1KW→1ランキング」ではなく、「1KW→N個のサブクエリ→N×M件のページ→1つの統合回答」という多対多→統合型の構造に置き換わっているわけです。
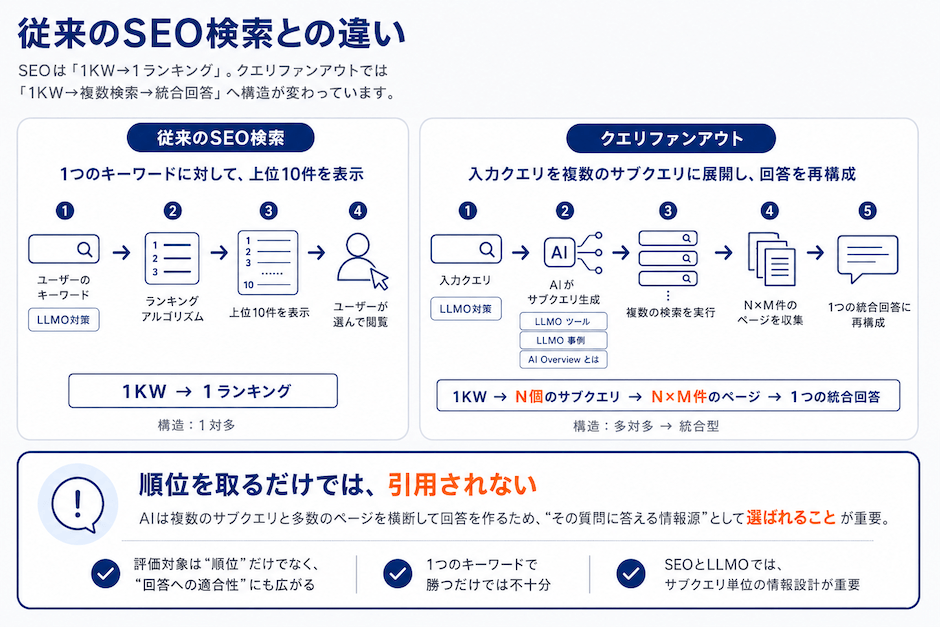
順位を取るだけでは引用されない、という現象はこの構造変化に起因します。
RAGとの関係性
クエリファンアウトとRAG(Retrieval-Augmented Generation: 検索拡張生成)は、似て非なる概念です。
RAGは「検索結果をLLMに与えて回答を生成する」枠組み全体を指し、クエリファンアウトはそのRetrievalフェーズを多重化する具体手法にあたります。つまりクエリファンアウトは「RAGの中のサブ技術」であり、両者は対立しません
arXiv:2402.03367(RAG-Fusion)はRAG文脈の中でクエリファンアウト型検索を提案した論文で、ChatGPT Search や Perplexity も大枠ではRAG型生成プロセスのなかでクエリファンアウトを採用しています。
RAGがAI検索全体に与える影響はBrightonSEO Spring 2025レポート|RAGがもたらすSEOの新潮流でAIエンジンが従来検索インデックスにどの程度依存しているかのデータを確認できます。
クエリファンアウトがSEO/LLMOに与える3つの影響
クエリファンアウトの普及により、SEO/LLMOの考え方には大きく3つの変化が起きています。
前述のクエリファンアウト採用事例で見た通り、対策対象は Google AI Mode/AI Overviews だけでなく ChatGPT Search・Perplexity・Microsoft Copilot・社内RAGアプリを含むLLM経由の検索チャネル全体です。
単一KW最適化からトピック面の最適化へ
「KW単体で順位を取る」発想は、サブクエリ群への網羅対応に置き換わります。
中心トピックを軸に「等価/追跡/一般化/特化」のサブクエリを配置するトピッククラスタ設計が前提になり、ピラーとサブページの内部リンク網が再評価されます。
具体的なクラスタ設計と内部リンクの貼り方は内部リンクの貼り方・設置場所|SEO効果の高い内部リンク施策で、「ピラーページ+クラスタページ」を内部リンクで束ねる実装例を確認できます。
流入数は減るが流入の質は上がる
AI回答内で完結する質問が増えるため、サイトへの直接流入数は減ります。一方で前述のGoogle公式ブログでは「AI Overviews表示クエリでGoogle利用が10%超増加」と発表されており、AI回答経由の需要そのものは増えています。
サイトに到達するユーザーは「長く具体的な質問を持つ高関心層」に絞り込まれるため、KPIは「流入数」より「コンバージョン率・行動深度」に置き換える必要があります。
当社が2026年3月に実施した調査「Google検索「AI概要」に関する検索行動実態調査(全国1,104名対象)」でも、AI Overview経由クリックの23.2%がコンバージョンに至り、ユーザーの46.96%がクリック前にブランド名を確認していることが確認されています。「流入の質」と「ブランド認知」が同時に効く構図です。
一次情報・E-E-A-Tの重要性が増す
統合フェーズでAIが引用ソースを選別するときに、一次情報・専門家署名・経験記述・外部サイテーションは重要なシグナルになります。
本記事のように特許番号・arXiv番号を本文中で明示する書き方は、AI側に「一次情報を持つコンテンツ」と判定されやすい材料となります。
さらにデータボイド戦略=情報空白地帯戦略は、(検索需要はあるがWeb上に良質情報がほぼないクエリにニッチ一次情報をぶつける)は、ドメインオーソリティの低い中小サイトでもAI回答に採用されやすい勝ち筋になります。
「SEOがLLMO時代に不要になるのか」については「SEOはもう意味がない」は本当か?GEO/LLMO時代の誤解と本質で、SEOで蓄積されたE-E-A-T評価がそのままAI引用シグナルとして効く仕組みについても解説しています。
クエリファンアウトにおけるサブクエリの種類とパターン
AIが裏で生成するサブクエリは、形のうえで大きく8パターンに分類できます。
前述のGoogle特許群(US20240289407A1 のsynthetic queries、US12158907B1 のサブテーマ生成、US8667003B1 のsibling refinementsなど)に登場するサブクエリの種類を、LLMO実務で使いやすい形に整理したものです。
8分類の概要(特化/含意/明確化が主軸)
メインクエリを「クエリファンアウト 対策」とした場合に、AIが内部で生成しうるサブクエリの例を一覧化します。

| # | パターン名 | 役割(=どんな検索か) | 発行例 |
|---|---|---|---|
| 1 | 等価(Equivalent) | 同義の言い換え | 「query fan-out 対応方法」 |
| 2 | 追跡(Follow-up) | 次の質問 | 「クエリファンアウトとAI Modeの違い」 |
| 3 | 一般化(Generalization) | 上位概念に広げる | 「LLMO対策とは」 |
| 4 | 特化(Specification) | より具体化 | 「クエリファンアウト 中小サイト 対策」 |
| 5 | 正規化(Canonicalization) | 標準形式に揃える | 「クエリファンアウト Google 公式」 |
| 6 | 翻訳(Translation) | 多言語化 | “query fan-out optimization Japanese” |
| 7 | 含意(Entailment) | 暗黙の論理を補う | 「AI検索 流入減少 対策」 |
| 8 | 明確化(Clarification) | 曖昧さの解消 | 「クエリファンアウト それともAI Overview?」 |
LLMO担当者が特に注意すべき3パターン
8パターン全部を覚える必要はありません。SEO/LLMO の対策で特に効くのは特化・含意・明確化の3つです。
- 特化: 「best X for Y」型のクエリで頻発。長尾KWを網羅していると拾われやすい
- 含意: 「X 影響 対策」のように原因→結果の構造を持つクエリで発行。論理構造のある記事が有利
- 明確化: 曖昧な短い質問で発行。FAQセクションが直接ヒットしやすい
実務的には、自社のターゲットKWを上記8パターンで言い換え、「どのサブクエリで自社ページが拾われそうか」をマッピングするサブクエリ・カバレッジ・チェックが出発点になります。
前段の「メインKW→関連KW→共起語」基本設計はSEOキーワードの入れ方解説|検索上位が実施している設定方法で押さえておくと、サブクエリ・マッピング作業がスムーズです。
ブランド指名検索KWがサブクエリに含まれるケース
8分類に含まれる「特化」「正規化」サブクエリの一種として、見落とされがちな重要な現象がブランド指名検索KWがサブクエリに自動的に含まれるケースです。
たとえば「SEOツール おすすめ」と検索すると、AIは内部で次のようなサブクエリを自動生成することがあります。
- 「SEOツール 比較」
- 「[SEOツール名] 評判」
- 「[SEOツール名] 機能」
- 「[SEOツール名] 価格」
ユーザーが特定ブランド名を入れていなくても、
AIが「定番ブランド」を自分で連想してサブクエリ化するわけです。メカニズムは2つの組み合わせです。
- エンティティ認識: AIは Knowledge Graph などに登録されたブランドを「カテゴリの代表エンティティ」として認識している
- 特化・正規化サブクエリの生成: 前述の特許 US20240289407A1のsynthetic queries 生成プロセスで、入力クエリの意図が「比較・推薦・選定」のときに特定エンティティを含むサブクエリが組み立てられやすい
要するに、「比較・おすすめ・ベスト」型の質問のとき、AIは既知の有力ブランドを内部で勝手に呼び出すということです。
比較記事内での掲載順位とAI推薦の関係は生成AIは比較記事の上位ブランドを推奨しやすい(MIT・ハーバード大学研究)でポジションバイアスの実証研究を確認できます。
この現象から導かれるLLMO戦略の転換は次の通りです。
- 「検索順位を上げる」ではなく「サブクエリ発行段階でAIに想起される存在になる」ことが上流のKPI
- 自社サイト内のSEOだけでは指名サブクエリは発生しない
- 第三者メディアでの言及(PR、寄稿、業界レポート掲載、被リンク獲得)の比重が増す
- Wikipedia、構造化データのOrganizationスキーマ、SNS公式アカウントなどのエンティティ整備が前提条件
つまりクエリファンアウト時代のLLMOは、自社サイト最適化を超えて「ブランドエンティティそのものをWeb全体に育てる」戦略にシフトします。
「自社ブランド名がAIに認識されている状態」が、クエリファンアウト時代の上流対策です。
クエリファンアウト時代のLLMO露出2形態(AI引用 vs AIブランド推薦)
これまで紹介したLLMO/SEOへの影響を踏まえると、追うべきKPIは2つに分かれます。LLMO担当者が混同しがちな重要な区別が、AI引用(Source Citation)とAIブランド推薦(Brand Mention)は別物だという点です。

両者は計測方法も対策アプローチも違うため、別個のKPIとして運用します。
AI引用(情報源として参照される)
AI引用とは、AIの回答末尾や脚注に「出典として」自社サイトのURLが表示されることを指します。
たとえば「LLMOコンサル会社 おすすめ」と検索したときに、回答末尾に「出典: mediareach.co.jp」とURLが付くのが引用です。
AI引用獲得の中核は情報構造の最適化です。引用されやすい見出しの作り方、見出し直後の結論要約、Schema.orgの整備、E-E-A-Tシグナルの強化が効きます。
短期施策の効果は中程度(数週間〜2ヶ月)で動き始めるのが当社現場の感触です。
AIブランド推薦(回答内でブランド名が登場する)
AIブランド推薦とは、AIの回答本文中に「自社ブランド名」が登場することを指します。AI回答中に「メディアリーチ」というブランド名が出るのが推薦です。
両方とれるのが理想ですが、片方だけしか取れないケースも頻発します。
AIブランド推薦獲得の中核はエンティティ強化です。Wikipedia整備、構造化データのOrganization/Personスキーマ、第三者メディア露出、業界アワードやランキング獲得、PR施策が効きます。
短期施策ではほぼ動かず、PR施策込みで6ヶ月以上の助走が必要というのが当社現場の感触です。
比較表とKPI設計
| 観点 | AI引用(Citation) | AIブランド推薦(Mention) |
|---|---|---|
| 露出形式 | 出典URLとして明示 | 本文中のブランド名言及 |
| 主要KPI | Citation Rate(引用率)、引用位置 | Mention Share(言及シェア)、Sentiment |
| 主な対策 | 情報構造の最適化、結論先出し見出し | エンティティ強化、サイテーション獲得 |
| 短期施策の効果 | 中(数週間〜2ヶ月) | 低(3〜6ヶ月) |
| 計測ツール例 | Peec、LLM Pulse、Siftly、Stackmatix | Peec、LLM Pulse、AirOps、Passionfruit |
KPI設計時に最も重要なのは、引用と推薦を1つのスコアに合算しないことです。両者は独立指標として運用し、月次トレンドを並列で追います。具体的な運用は次の通りです。
基本セット: Citation Rate(自社)/ Mention Share(自社・競合上位3社)
【メディアリーチの現場見解】
当社のLLMOコンサル現場では、AIブランド推薦は短期施策ではほぼ動かず、PR施策込みで6ヶ月以上の助走が必要です。一方AI引用は構造改修+3ヶ月程度のコンテンツ施策で動きやすい、という構造的非対称性を観測しています(推定。当社運用案件20数件からの定性的観察)。短期成果を優先する案件では引用獲得を、年間で指名想起シェアを伸ばしたい案件では推薦獲得を、プロジェクトの時間軸に応じて使い分けるのが現実的です。
引用率と言及シェアを計測するツール選定はLLMO対策ツールおすすめ厳選5選|AI引用・ブランド推薦の計測・分析(2026年版)で、Ahrefs ブランドレーダー/Semrush One/Profound/Otterly.ai/Peecの機能比較を確認できます。手元の現状把握はURLを入れるだけで分かるLLMO無料診断ツールから始めるのが手早いです。
クエリファンアウト時代のLLMO実装ステップ(10項目チェックリスト)
実装は優先順位の高い順に10項目で整理します。Google AI Mode単体ではなく ChatGPT Search・Perplexity・Microsoft Copilotを横断して評価できる設計にしておくのが前提です。
トピッククラスタとサブクエリ網羅(項目1〜3)
- 中心トピックの再定義: 自社事業ドメインで最も強い1〜3トピックを特定する
- サブクエリのマッピング: 8分類(等価/追跡/一般化/特化/正規化/翻訳/含意/明確化)でターゲットKWを言い換え、カバー漏れを可視化する
- ピラーとサブページの再編: ピラーから各サブクエリへ内部リンクで接続し、薄い記事は統合・論点混在の厚い記事は分解する
引用トリガー型の見出しと構造化データ(項目4〜7)
- 結論先出し型の見出し: 定義/比較/手順/事例/リスト/統計/原因/Yes-Noを記事種別に応じて選定する
- 見出し直後の結論要約: H2・H3の直後に1〜2文の結論を必ず置く
- Schema.org の整備: Article、FAQPage、HowTo、Organization、Personを記事タイプに応じて適用する
- エンティティ整合: Wikipedia、SNS公式アカウント、Google Business Profile、構造化データの記述を一致させる
llms.txtのような新興規格をどこまで実装すべきか迷う場合はLLMOで注目される「llms.txt」とは?書き方・作り方やメリット・効果も合わせて確認すると、現時点での費用対効果の判断軸が得られます。
2026年現在では、llms.txtの効果は公式には公表されておらず必要性は
ブランド指名サブクエリ獲得とAI引用×AI推薦の二軸KPI(項目8〜10)
- サイテーション獲得: 第三者メディア寄稿・業界レポート掲載・アワード受賞などで「ブランド名×カテゴリ」の言及を増やす
- 複数LLM横断のプロンプトセット運用: Google AI Mode/ChatGPT Search/Perplexity/Microsoft Copilot 共通の評価プロンプト群を50〜200件用意する
- 二軸KPI運用: Citation Rate(引用率)と Mention Share(推薦シェア)を別個のダッシュボードで月次運用する
プロンプトセットの設計(戦略的絞り込みと10回計測)の具体手順はLLMOプロンプト設計戦略・手順を解説|2つのステップで進める実務ガイドに整理されているので、項目9を実装する際の手引きとして活用できます。
一次情報まとめ:クエリファンアウト関連の特許・論文ソース
ここまで引用してきた一次情報を、後から検証できるように特許・論文単位で整理しておきます。初級〜中級者は「全部読む」必要はなく、どの主張がどの一次情報に紐づいているかを確認できれば十分です。
Google特許 4件
| # | 特許番号 | タイトル | 押さえるべきポイント |
|---|---|---|---|
| 1 | WO2024064249A1 | Prompt-based query generation for diverse retrieval(PROMPTAGATOR) | 2〜8件のアノテーション例だけでLLMが合成クエリを生成する基本アイデア。クエリファンアウトの土台 |
| 2 | US20240289407A1 | Search with stateful chat | AI Modeに最も近いシステム設計。「synthetic queries」「additional/alternative queries」を明文化 |
| 3 | US12158907B1 | Thematic Search | サブテーマ単位の検索アーキテクチャ。AI Modeのフォローアップ機能の論拠 |
| 4 | US8667003B1 | Generating sibling query refinements | 「fan-out measure」というフレーズが直接登場(2014年公開)。Googleが10年以上前から保有していたアイデア |
arXiv論文 3件
- arXiv:2402.03367(RAG-Fusion, Rackauckas 2024): クエリファンアウトの「並列検索+融合」をアカデミックに記述した最初期の論文
- arXiv:2412.17558(A Survey of Query Optimization in LLMs、2024年): クエリ最適化全般の包括サーベイ
- arXiv:2509.07794(Query Expansion Survey、2025年): LLMによるクエリ拡張をRAG文脈で総覧
Google公式 / 各社公式
- Google公式ブログ “AI Mode in Search update”(I/O 2025)
- OpenAI “Introducing ChatGPT search”
- Perplexity “What is Pro Search”
- Microsoft Bing Generative Search 公式発表
- Anthropic Claude Web Search Tool 公式ドキュメント
特許の原文を確認したいときは patents.google.com または USPTO(米国特許商標庁) や WIPO(世界知的所有権機関) のDBで番号検索すれば該当特許にアクセスできます。
クエリファンアウト時代を勝ち抜くLLMO設計のはじめかた
クエリファンアウトはGoogle AI Modeの中核技術であると同時に、ChatGPT Search・Perplexity・Microsoft Copilot・OSSのRAGフレームワーク・エンタープライズ検索まで横断するLLM時代の汎用検索パターンです。
仕組みを正確に理解することで、Google単体ではなくLLM/RAGエコシステム全体を相手にしたLLMO戦略へ移行できます。
本記事のようにGoogle特許4件とarXiv論文を起点に整理すると、競合記事の多くが触れていない「ブランド指名サブクエリ」と「AI引用 vs AIブランド推薦」の論点までカバーできます。
実装段階では、トピッククラスタの再設計から二軸KPI運用までを優先順位順に進めることが現実的です。
自社単独で設計から実装まで進めようとするとサブクエリ・マッピングの解像度や構造化データの実装精度で詰まりがちです。
LLMO自体に着手すべきかの判断軸はLLMOは、やるべき?盛り上がりの波で見る「現在地」と「未来」で、ハイプサイクルと自社事業を重ね合わせるフレームを確認できます。「クエリファンアウト時代の対策、何から始めればいいか分からない」方は、当社メディアリーチのLLMO診断サービスで引用×推薦の二軸を可視化するところから始めるのがおすすめです。
本格的な戦略設計・運用支援はLLMOコンサルティングサービスまでお問い合わせください。
よくある質問(FAQ)
Q: クエリファンアウトとAI Overviewはどう違いますか?
A: クエリファンアウトはAIが1つのクエリを複数のサブクエリに分解して並列検索する技術プロセスであり、AI OverviewはGoogle検索結果上部に表示されるAI生成の要約UIです。AI OverviewやAI Modeの裏側でクエリファンアウトが動いている、という関係です。なおLLMO・AIO・GEOといった呼称の違いについてはLLMO、AIO、GEOの違いとは?AI検索対策はなぜ呼び方が変わるのかで整理しています。
Q: クエリファンアウトに対応するために、まず何から着手すべきですか?
A: 既存トピックを「中心トピック→サブクエリ群」の2層で再設計するところから始めるのが定石です。次にH2/H3の直後に結論要約を置き、引用されやすい見出しに整え、AI引用とAIブランド推薦のKPIを別々に設定します。
Q: ブランド名がサブクエリに含まれているかを観測する方法はありますか?
A: Google AI Modeで比較・推薦の意図のテストプロンプトを投入し、AI回答内に自社ブランド名が言及されるかを定点観測する方法が有効です。市販のLLM可視化ツール(Peec、LLM Pulse等)を併用すれば、競合との比較が定量的に可能です。
Q: AI引用とAIブランド推薦のどちらを優先すべきですか?
A: 業態によります。情報提供型サイト(メディア、解説サイト)はAI引用優先、ECや士業・コンサルなど指名想起が成果に直結する業態はAIブランド推薦優先が基本です。理想は両軸を別KPIで運用し、相関を見ながらバランスを取ることです。
Q: クエリファンアウトはRAGと同じ技術ですか?/Google AI Mode専用ですか?
A: 同義ではないものの密接に関係し、Google専用でもありません。RAGは「検索結果をLLMに与えて回答生成する」枠組みで、クエリファンアウトはそのRetrieval(検索)プロセスを多重化する具体手法です。
学術的にはarXiv:2402.03367(RAG-Fusion論文)が同様の手法を記述しており、LangChain MultiQueryRetriever・LlamaIndex SubQuestionQueryEngine としてOSSに標準実装されています。Google AI Modeはこの汎用パターンを商用規模で実装した一例で、LLMO戦略では複数エンジン横断のCitation/Mention計測が前提です。
本記事の内容には万全を期しておりますが、情報の正確性や完全性を保証するものではありません。万が一、誤りや不適切な表現等を発見された場合は、以下の方法でご連絡いただけますと幸いです。


